When choosing between big data frameworks and data analytics solutions — a comparison between Hadoop and Spark is bound to happen.
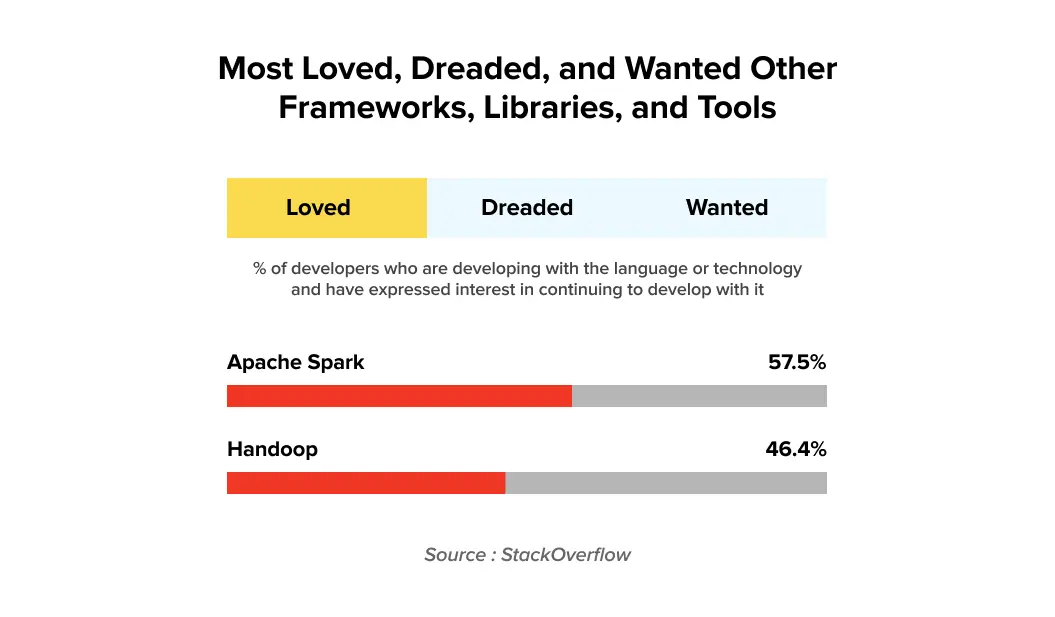
According to Stack Overflow Developer’s survey, 57.5% of developers love Apache Spark, whereas 46.4% of developers show love for Hadoop.
Let us discuss each of the open-source frameworks in detail while also understanding the difference between the two.
What is the Difference Between Hadoop and Spark?
Before we move ahead with highlighting the difference between Hadoop vs Spark, here’s an individual overview for both the frameworks.
1. What is Apache Hadoop?
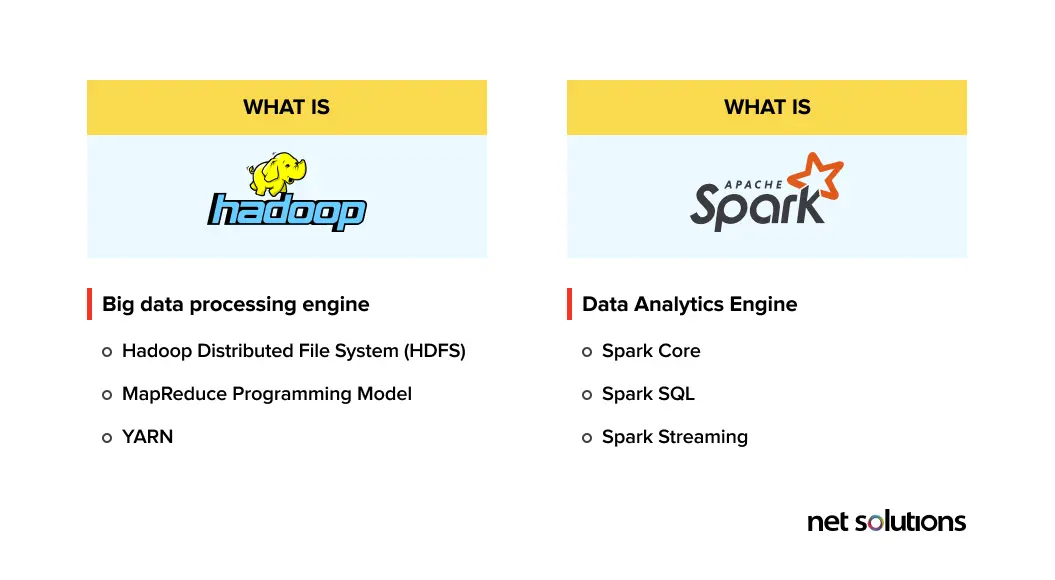
Big data processing engine
Hadoop is an open-source software framework that facilitates software to store and process volumes of data in a distributed environment across a network of computers.
It is designed to focus on scaling the power of individual servers, i.e., each server has its computational power and storage capacity.
Several parts make up the Hadoop framework, which includes:
- Hadoop Distributed File System (HDFS): Stores files in Hadoop centric format and places them across the Hadoop cluster where they provide high bandwidth
- MapReduce Programming Model: This is a Hadoop feature that facilitates a batch engine to process large scale data in Hadoop clusters
- YARN: A platform for managing computing resources within the Hadoop clusters
2. What is Apache Spark?
Data Analytics Engine
Spark is an open-source cluster computing framework that mainly focuses on fast computation, i.e., improving the application’s speed. Apache Spark minimizes the read/write operations to disk-based systems and speeds up in-memory processing.
The Apache Foundation introduced it as an extension to Hadoop to speed up its computational processes. Spark supports exclusive cluster management and uses Hadoop for storage.
Significant components of Spark include:
- Spark Core: This facilitates task dispatching, several input/output functionalities, and task scheduling with an application programming interface
- Spark SQL: Supports DataFrames (data abstraction model) that, in turn, provides support for both structured and unstructured data
- Spark Streaming: This deploys Spark’s fast scheduling power to facilitate streaming analytics
Hadoop vs Spark: Comparison
Here are the key differences between Hadoop and Spark, based on the following parameters:
1. Performance
Spark is lightning-fast and is more favorable than the Hadoop framework. It runs 100 times faster in-memory and ten times faster on disk. Moreover, it sorts 100 TB of data 3 times faster than Hadoop using 10X fewer machines.
The reason behind Spark being so fast is that it processes everything in memory. Spark, mainly, is faster on machine learning applications, like Naive Bayes and k-means. Thanks to Spark’s in-memory processing, it delivers real-time analytics for data from marketing campaigns, IoT sensors, machine learning libraries, and social media sites.
However, if Spark, along with other shared services, runs on YARN, its performance might degrade and lead to RAM overhead memory leaks. And in this particular scenario, Hadoop performs better. If your organization focuses on batch processing, Hadoop is much more efficient than its counterpart.
Hadoop is a big data framework that was never built for lightning speed — its primary focus is to identify and gather information from websites about the data that is no longer required or will go obsolete in the time to come.
Takeaway: Both Hadoop and Spark have a different way of processing. Thus, it entirely depends on the requirement of the project requirements when choosing between Spark and Hadoop for memory processing.
2. Security
Spark’s security is still in its emergence stage, supporting authentication only via shared secret (password authentication). Even Apache Spark’s official website claims, “There are many different types of security concerns. Spark does not necessarily protect against all things.”
Hadoop, on the other hand, has better security features than Spark. The security benefits—Hadoop Authentication, Hadoop Authorization, Hadoop Auditing, and Hadoop Encryption gets integrated effectively with Hadoop security projects like Knox Gateway and Sentry.
Takeaway: In the Hadoop vs Spark Security battle, Spark is a little less secure than Hadoop. However, by integrating Spark with Hadoop, it can use the security features of Hadoop.
3. Cost
Hadoop and Spark are open-source frameworks, use commodity servers, involve cloud computing, and have similar hardware requirements. Thus, it is taxing to compare Spark and Hadoop on a cost basis.
However, Spark makes use of huge amounts of RAM to run everything in memory. And RAM has a higher price associated with it than hard-disks.
On the other hand, Hadoop is disk-based. Thus, your cost of buying an expensive RAM gets saved. However, Hadoop needs more systems to distribute the disk I/O over multiple systems.
Therefore, when comparing Hadoop and Spark big data frameworks on cost parameters, organizations must analyze their functional vs. business requirements.
If your requirement involves — processing large amounts of historical big data — Hadoop is the way to go because hard disk space comes at a much lower price than memory space.
On the contrary, in Spark’s case, it can be cost-effective when dealing with real-time data as it uses less hardware to perform the same tasks at a much faster rate.
Takeaway: In Hadoop vs Spark cost battle, Hadoop costs less, and Spark is comparatively expensive due to its in-memory solution.
4. Ease of Use
One of the biggest USPs of the Spark framework is its ease of use. Spark has user-friendly and comfortable APIs for its native language Scala and Java, Python web development, and Spark SQL (also known as Shark).
The simple building blocks of Spark make it easy to write user-defined functions. Moreover, since Spark allows for batch processing and accommodation of machine learning algorithms, it becomes easy to simplify data processing infrastructure. It even includes an interactive mode for running commands with immediate feedback.
On the other hand, Hadoop is a Java big data framework and makes it challenging to write a program with no interaction mode. Although Pig (an add-on tool) makes it easier to program, it might take longer to learn it.
Takeaway: In the ‘Ease of Use’ Hadoop vs Spark battle, Spark is easier to program and includes an interactive mode for the user’s convenience.
Is it Possible for Apache Hadoop and Spark to Have a Synergic Relationship?
Yes, this is entirely practical. Let’s get into the details on how they can work in tandem.
Apache Hadoop ecosystem includes HDFS (Hadoop Distributed File System), Apache Query, and HIVE. Let’s see how Apache Spark can make use of them.
An Amalgamation of Apache Spark and HDFS
The purpose of Apache Spark is to process data. However, to process data, the engine needs the input of data from storage. And for this purpose, Spark uses HDFS (not the only option, but the most popular one since Apache is the brain behind both of them).
Apache Spark and Apache Hive are highly compatible as together they can solve many business problems.
For instance, a business is analyzing consumer behavior — the company will need to gather data from various sources like social media, comments, clickstream data, customer mobile apps, and many more.
Now, an intelligent move by the organization will be to use HDFS to store the data and Apache hive as a bridge between HDFS and Spark.
Example: Uber and its Amalgamated Approach
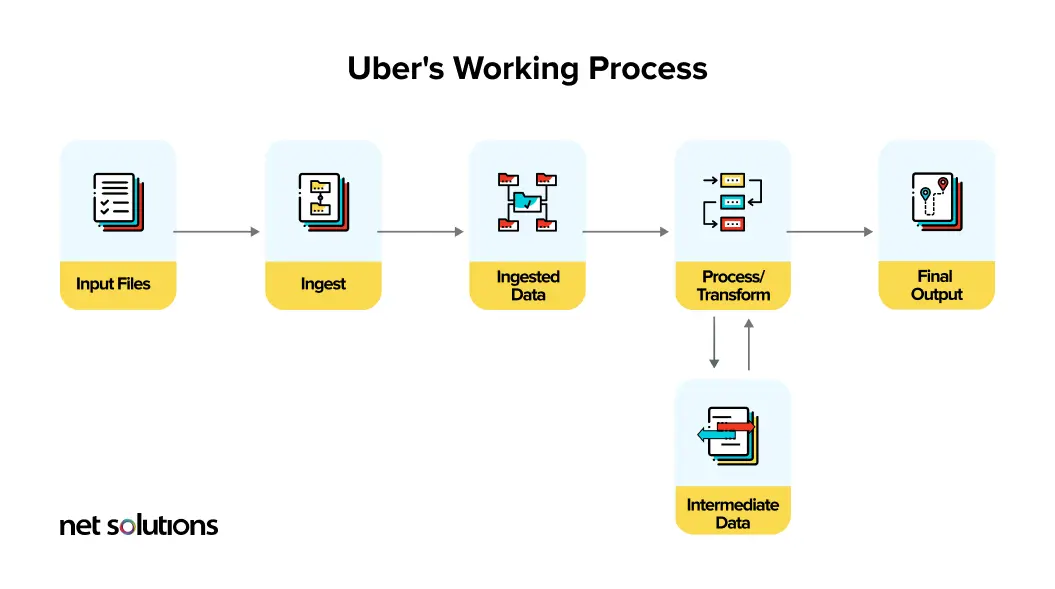
To process the big data coming from several sources, Uber uses a combination of Spark and Hadoop. It uses Hadoop for data analytics to provide accurate traffic data in real time. Uber uses HDFS to upload raw data into Hive and Spark to process billions of events.
Hadoop Vs Spark: Comparison Table
Here’s a comparison table that summarizes the differences between Hadoop and Spark:
| 1. Intent | Data Processing Engine | Data Analytics Engine |
| 2. Work Process | Analyses batches of data present in huge volumes | Analyses and processes real-time data |
| 3. Processing Style | Batch mode | real-time data handling |
| 4. Latency | High | Low |
| 5. Scalability | It only requires the addition of nodes and disks, which makes it quickly scalable | Complex scalability due to more reliability on RAM |
| 6. Cost | Less costly due to the MapReduce Model | Is more expensive due to its in-memory solution |
| 7. Security | More secure | Less Secure |
| 8. Ease of Use | Complex to use | Easier to use |
Which one is Better: Hadoop or Spark?
While Spark is faster than thunder and is easy to use, Hadoop comes with robust security, mammoth storage capacity, and low-cost batch processing capabilities. Choosing one out of two depends entirely upon your project’s requirement, the other alternative being combining parts of Hadoop and Spark to give birth to an unbeatable combination.
You can also consider using both Hadoop and Spark and get the best of two worlds experience and can call this new framework Spoop.