
Retrieval-Augmented Generation (RAG) supercharges LLMs with real-time, domain-specific knowledge, making them more accurate, relevant, and commercially viable. For eCommerce teams dealing with dynamic catalogs, localized campaigns, or rich media, RAG unlocks next-level personalization and smarter automation.
But here’s the catch: RAG’s power comes with cost complexity. From compute and storage to embeddings and inference, the expenses can quickly snowball without clear oversight. For CTOs, Tech Architects, and Product Leaders in retail, RAG presents a unique opportunity to scale personalization, automate content discovery, and supercharge internal knowledge systems—but only if the cost is well understood and controlled. Without a clear understanding of the actual costs, businesses risk misallocating resources and failing to meet ROI targets.
RAG’s operational expenses span several components: compute for processing and querying, storage for large and vectorized datasets, embedding generation, and ongoing LLM inference. Additional costs include data transfer fees and ongoing system monitoring and maintenance costs, making it essential to evaluate the full cost of ownership from the outset.
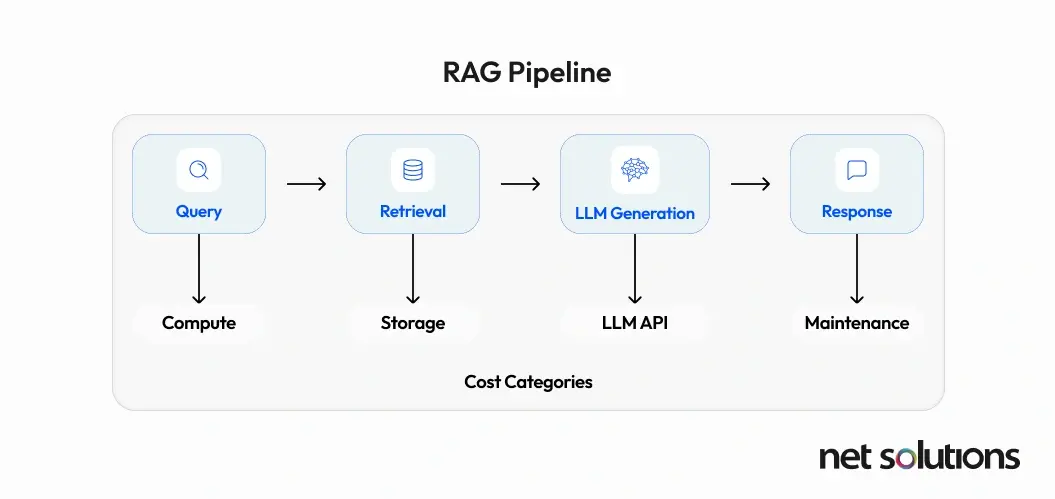
The Core Components of RAG Operational Costs
A RAG pipeline is an intricate system, and its operational costs stem from several fundamental components, each with its own pricing dynamics and optimization opportunities.
1. Compute Resources
At the heart of every RAG pipeline lies one critical dependency: compute power. Whether you’re running in the cloud or on-premise, compute resources are essential for keeping the entire system responsive, scalable, and intelligent.
What Compute Powers in a RAG Pipeline
Compute resources are responsible for running the three core functional blocks of your pipeline:
- Embedding Engine: Converts raw data (text, images, audio, etc.) into dense vector representations that LLMs can reason over.
- Vector Database: Stores high-dimensional embeddings and enables similarity-based retrieval.
- Query Processing Unit: Parses incoming queries, generates embeddings, and coordinates the retrieval + LLM response generation.
What Influences Compute Costs
The cost of compute isn’t static; it fluctuates depending on:
- Pipeline scale – The number of queries, size of the dataset, and user load.
- Task complexity – More advanced NLP, multimodal processing, or post-processing layers demand more compute.
- Performance targets – Stricter latency requirements drive the need for high-speed, low-latency infrastructure.
Why Latency Drives Cost
One of the most important considerations in RAG is latency: how fast the system can deliver a relevant response. For real-time use cases like customer support chatbots, product search and discovery, live personalization, or Q&A tools, businesses often need to keep response times below 10 milliseconds. Achieving this kind of performance usually requires:
- Performance-optimized compute units (e.g., GPUs, high-memory CPUs)
- Specialized, high-throughput infrastructure
The Trade-Off: Speed vs Spend
There’s a clear trade-off: Faster responses = More powerful compute = Higher costs. Understanding this balance between responsiveness and infrastructure cost is key to architecting a sustainable, production-grade RAG system—especially for use cases where speed equals user satisfaction.
2. Data Storage & Retrieval
Once raw data is transformed into numerical embeddings, it must be efficiently stored in a vector database to facilitate rapid retrieval during user queries. The costs for storing this data are primarily influenced by two factors: the sheer number of vectors and their dimensionality (the number of numerical values representing each vector). A higher count of vectors or higher dimensionality generally means greater storage requirements and thus higher costs.
Retrieval costs, distinct from storage, are driven by the frequency and complexity of the queries themselves, as these operations demand dedicated compute resources for efficient processing. As RAG applications scale and handle higher query volumes, these retrieval expenses can escalate significantly.
Several prominent vector database providers offer varying pricing models:
- Weaviate Cloud (Serverless): Starts at $25/month + $0.095 per 1M vector dimensions stored monthly. Enterprise Cloud starts at $2.64 per AI Unit (AIU), with tiered storage options (Hot, Warm, Cold, Archive).
- Pinecone: Standard plan starts at $50/month minimum, then pay-as-you-go. Enterprise plans start at $500/month. Storage is ~$0.33/GB/month, with separate read/write charges.
- Qdrant Cloud: Offers a free 1GB cluster. Managed cloud and hybrid services start at ~$0.014/hour, depending on RAM, CPU, and storage allocated.
- AWS S3 Vectors: Optimized for large-scale vector storage with cost savings of up to 90% when paired with Bedrock Knowledge Bases. Fully managed, no provisioning needed.
Modern platforms like AWS Bedrock provide managed knowledge bases and vector storage, automating indexing and retrieval so you can scale up or down without guessing capacity. Likewise, a serverless infrastructure dynamically scales with demand, reducing computational and financial overhead while shortening time‑to‑market.
3. Embedding Costs
The process of embedding involves converting raw, unstructured data—whether text, images, audio, or video—into numerical vector representations. These vectors are fundamental for enabling semantic search capabilities within a RAG system. This step typically requires breaking down content into smaller, manageable chunks before converting them into high-dimensional numerical representations.
Current pricing examples for embedding services include:
- OpenAI: ~$0.10 per million tokens.
- Google Gemini (gemini-embedding-001): $0.15 per 1 million input tokens.
- Weaviate Embeddings: $0.025–$0.040 per 1 million tokens (includes models like Snowflake).
An often-underestimated cost lever in RAG is the chunking strategy. As observed, “Smaller chunks give you more precise search results but increase costs since you’ll have more vectors to store and search. Larger chunks reduce costs but might make it harder to find specific information”.
The “optimal” chunk size is not a one-size-fits-all solution; rather, it represents a careful balance between achieving precise search results and managing operational expenses. Fine-tuning these chunking strategies is therefore a critical optimization technique that directly influences embedding, storage, and retrieval expenditures, extending beyond a mere data preparation step.
4. LLM Inference Costs
Generating responses using a Large Language Model is frequently the most substantial contributor to the total operational costs of a RAG pipeline.
For API-based models, such as those offered by OpenAI GPT or Google Gemini, pricing is typically based on the number of tokens processed during each query. This includes both the input tokens (the augmented prompt provided to the LLM) and the output tokens (the response generated by the LLM). Consequently, longer prompts or requests that necessitate more detailed and extensive responses will incur higher costs. However, when RAG is applied strategically, especially in regulated sectors like finance, it can significantly reduce token waste by grounding the LLM in a reliable context. RAG-based LLMs in finance help minimize hallucinations and optimize inference by streamlining token usage and ensuring more focused outputs.
Examples of LLM inference pricing include:
- Google Gemini 1.5 Pro: Input tokens range from $1.25 to $2.50 per 1 million tokens, while output tokens are significantly higher, ranging from $10.00 to $15.00 per 1 million tokens, with pricing tiers dependent on the prompt length.
- Google Gemini 1.5 Flash: Offers more economical rates, with input tokens at $0.30 per 1 million (for text, image, or video) and $1.00 per 1 million (for audio). Output tokens are priced at $2.50 per 1 million.
- OpenAI: While specific per-token rates for text models are not detailed in the provided information, it is stated that “Prompts are billed similarly to other GPT models,” implying a token-based pricing structure.
5. Network Transfer Fees
Network transfer fees are an often-overlooked but potentially significant component of RAG operational costs. These charges apply as data moves between different components within the RAG pipeline, especially when these components are distributed across various services or geographical regions. In cloud environments, a common pricing pattern is that data ingress (data flowing into the cloud) is either free or very inexpensive, while data egress (data flowing out of the cloud) can be a substantial “hidden gotcha”. High volumes of data moving between cloud regions, or from the cloud to on-premise systems, can quickly accumulate considerable network charges.
Self-Hosted vs. Commercial Hyperscaler Solutions: A Total Cost of Ownership (TCO) Analysis
The decision between deploying a RAG pipeline on-premise (self-hosted) or leveraging commercial hyperscaler cloud solutions (AWS, Azure, GCP) is a strategic one, heavily influenced by factors beyond just immediate operational costs. A comprehensive Total Cost of Ownership (TCO) analysis is essential for making an informed choice.
The Cloud Advantage: Flexibility and Scalability
Commercial hyperscalers offer compelling advantages in terms of flexibility, scalability, and reduced management overhead. Their pay-as-you-go models allow organizations to provision resources on demand, scaling up or down rapidly to match fluctuating workloads. This elasticity can significantly reduce idle costs, as businesses only pay for what they consume.
Managed RAG services, such as Amazon Bedrock Knowledge Bases, further simplify deployment by handling the underlying infrastructure and complexities, allowing developers to focus on application logic. These services also often provide built-in features for privacy and security, which are critical for sensitive data.
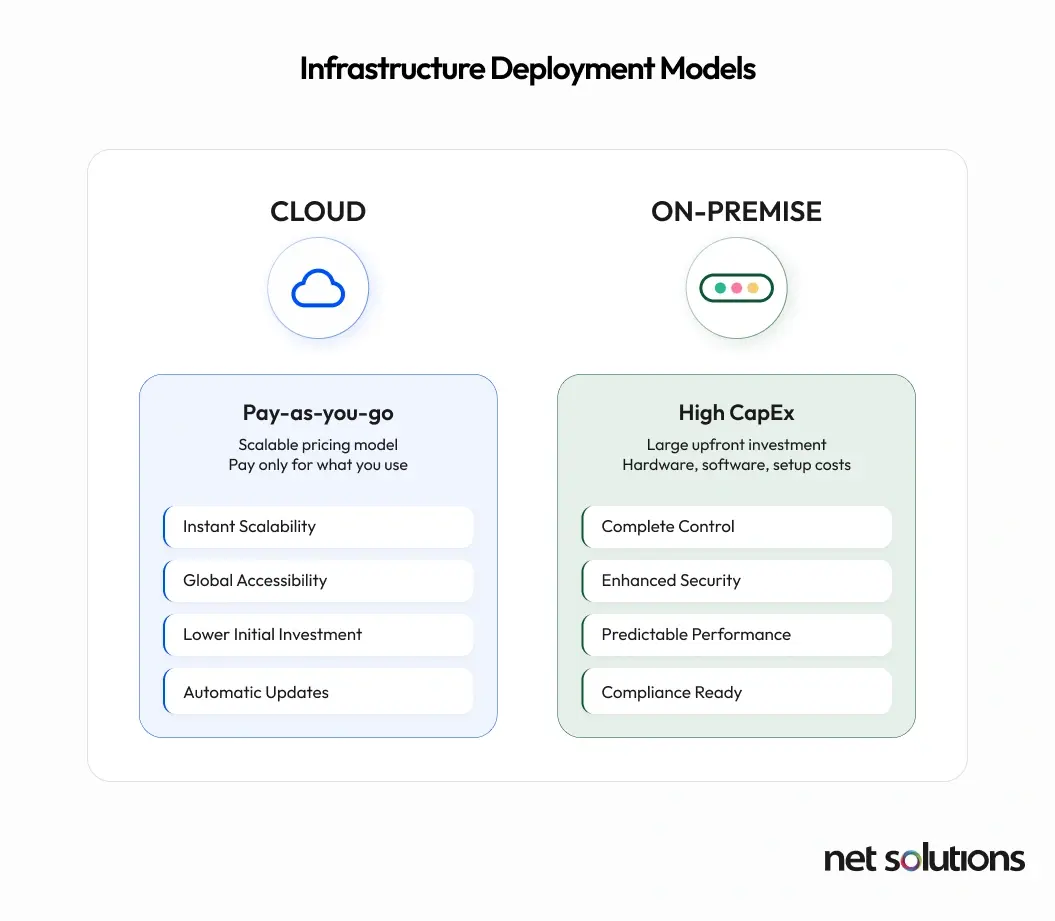
The On-Premise Reality: Control and Upfront Investment
For certain industries, particularly those with stringent regulatory requirements such as finance, healthcare, and defense, the ability to maintain granular control over data and infrastructure is paramount. These organizations often cannot transmit sensitive data to the cloud, making on-premise RAG a necessity.
However, this control comes with a significant financial commitment. On-premise RAG deployments necessitate substantial upfront capital expenditure (CapEx) for acquiring servers, high-performance GPUs or TPUs, specialized storage solutions (like NVMe drives for vector databases), and robust networking infrastructure (e.g., InfiniBand). Beyond hardware, there are also costs associated with physical infrastructure, such as data center space, power, and cooling.
The architectural complexity of on-premise RAG is also considerably higher. Unlike cloud environments, where services are readily available, an on-premise system must be architected from day one like a consumer-scale cloud service, often with no opportunity for gradual scaling. This demands full-stack engineering expertise, including optimized compute placement across CPUs and GPUs, and the development of robust ingest pipelines that handle tasks like optical character recognition (OCR), layout detection, and structural parsing.
TCO Comparison: When Does On-Premise Make Sense?
Choosing between cloud and on-premise deployment isn’t just a technical decision—it’s a financial one. A thorough Total Cost of Ownership (TCO) analysis can reveal where your long-term savings truly lie.
Cloud: Flexible, but Costly Over Time
Cloud platforms like AWS, Azure, and GCP are ideal for:
- Short-term or bursty workloads
- Teams without infrastructure expertise
- Rapid experimentation and scaling
But there’s a catch: their usage-based pricing can become expensive over time, especially for consistent, high-throughput applications. You pay for convenience, but at scale, that convenience compounds into cost.
On-Premise: Expensive Upfront, Efficient Long-Term
If your RAG workloads are predictable and continuous, an on-premise setup can offer:
- Fixed capital investment (CapEx) instead of variable operating costs
- Optimized GPU utilization over time
- Greater control over performance and data handling
Real-World Comparison
Consider a five-year TCO comparison for a single server with 8 NVIDIA H100 GPUs. An on-premise setup might cost approximately $871,912 (including initial hardware and estimated power/cooling), whereas running the equivalent on-demand cloud instance could amount to over $4,306,416. This demonstrates a potential saving of over $3.4 million over five years for the on-premise solution. Even with cloud commitment options like 1-year or 3-year Savings Plans, which reduce the cloud cost to around $3.39 million and $2.36 million, respectively, the on-premise solution often remains more cost-effective for sustained usage.
Hourly Utilization Threshold: The Break-Even Point
There’s a tipping point where on-prem becomes more economical:
- If your RAG pipeline runs 6–9 hours per day consistently, you’ll likely hit break-even versus cloud.
- Beyond that, the savings only increase.
This makes on-premise ideal for:
- Enterprise-grade, continuous RAG operations
- Regulated industries with strict data controls
- Teams aiming to reduce cloud dependency
One Caveat: Hosting Very Large LLMs
It is also important to acknowledge that self-hosting very large LLMs can still result in inferior performance or capabilities compared to commercial cloud options, primarily due to the immense GPU and RAM resources required by the largest models. However, for many common tasks, self-hosted 70B LLMs can be quite indistinguishable from commercial offerings, suggesting that smaller, specialized models can be competitive for on-premise deployment.
RAG for Audio / Video Transcription and Per-Session Cost Estimation
The power of RAG extends beyond traditional text-based applications, embracing multimodal data such as audio and video. This capability allows organizations to search and reason over rich, non-textual content, unlocking new possibilities for information retrieval and analysis. The applications for multimodal RAG are vast and impactful:
- Corporate Training & E-learning: Making extensive video training libraries fully searchable, allowing employees to quickly find relevant segments.
- Media & Entertainment: Instantly locating specific segments across hours of interviews or footage, identifying appearances of individuals or discussions on particular topics.
- Healthcare & Medical Research: Analyzing video recordings of medical procedures or doctor-patient conversations to pinpoint key moments or visual markers.
- Legal & Compliance: Searching through hours of video depositions or audio recordings for specific phrases, individuals, or presented evidence.
- Customer Support: Empowering support teams to rapidly find helpful moments, FAQs, or visual demonstrations from past video calls to resolve issues faster.
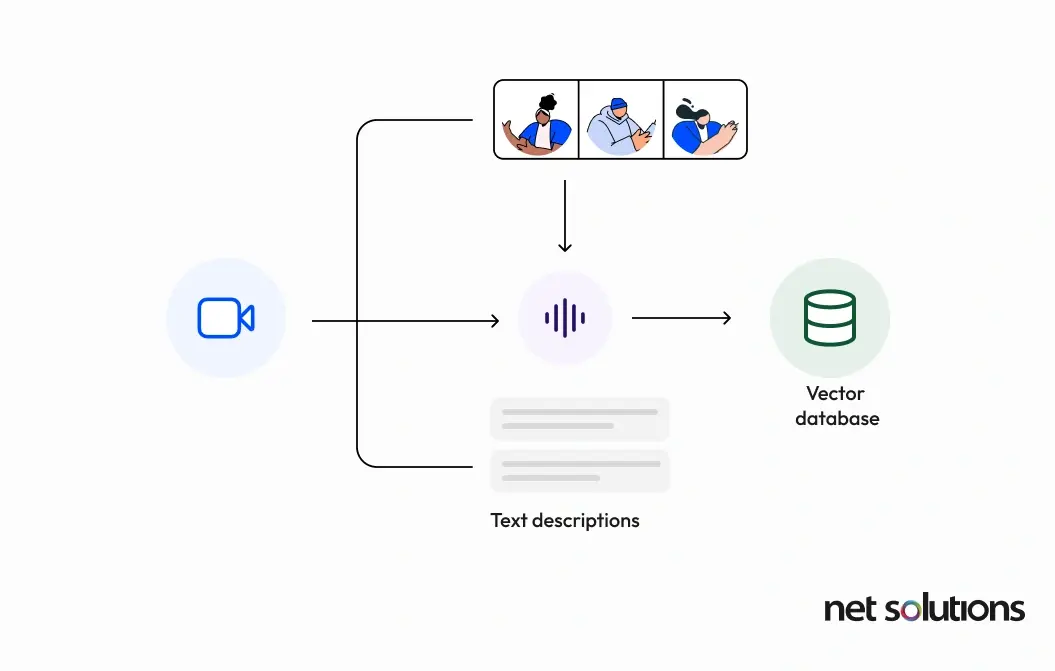
Per-Session Cost Estimation Example (Hypothetical)
Let’s estimate the per-session cost for a RAG pipeline designed to transcribe and summarize a 30-minute video meeting, and then allow for Q&A.
- Transcription: Using a cloud API like Google Cloud Speech-to-Text’s standard model at $0.016 per minute for a 30-minute video would cost $0.48.
- Visual Description: If the 30-minute video is broken into 15-second chunks, that’s 120 chunks. If a Vision LLM charges, for example, $0.005 per chunk for description, this would add $0.60 (120 chunks * $0.005/chunk). (Note: This is a hypothetical cost as detailed pricing for Vision LLM description per chunk is not provided in the research material.)
- Embedding: The combined text (transcript + visual descriptions) for a 30-minute meeting might be roughly 5,000 words, translating to approximately 7,000 tokens. Using Google Gemini Embedding at $0.15 per 1 million input tokens, the embedding cost would be negligible for a single session ($0.00105).
- LLM Inference (Summarization & Q&A):
- Summarization: Assume the combined input context (transcript + descriptions) is 50,000 tokens, and the generated summary is 5,000 tokens. Using Google Gemini 1.5 Flash:
- Input cost: 50,000 tokens * ($0.30 / 1,000,000 tokens) = $0.015
- Output cost: 5,000 tokens * ($2.50 / 1,000,000 tokens) = $0.0125
- Q&A: If a user asks 3 questions, each with a 500-token input and a 200-token output:
- Input cost: 3 * 500 tokens * ($0.30 / 1,000,000 tokens) = $0.00045
- Output cost: 3 * 200 tokens * ($2.50 / 1,000,000 tokens) = $0.0015
- Total LLM Inference: $0.015 + $0.0125 + $0.00045 + $0.0015 = $0.02945
- Summarization: Assume the combined input context (transcript + descriptions) is 50,000 tokens, and the generated summary is 5,000 tokens. Using Google Gemini 1.5 Flash:
Estimated Per-Session Cost: Roughly $0.48 (Transcription) + $0.60 (Visual Description – hypothetical) + $0.00105 (Embedding) + $0.02945 (LLM Inference) = ~$1.11 per 30-minute session
This example illustrates that while individual components might seem inexpensive, these costs accumulate rapidly with scale and frequency of use. The largest drivers for multimodal RAG are typically the transcription and visual processing, followed by LLM inference, especially if verbose outputs are generated.
Raw LLM vs. Framework-Based Implementations: Cost and Complexity
When building a RAG pipeline, developers face a crucial architectural decision: whether to integrate directly with raw LLM APIs and other foundational services, or to leverage higher-level, framework-based implementations. This choice has significant implications for development time, flexibility, and ultimately, operational costs.
A growing ecosystem of open-source RAG frameworks, including prominent names like LangChain, LlamaIndex, Dify, RAGFlow, and Haystack, has emerged to simplify the development of LLM-powered applications. These frameworks offer a structured approach, providing abstractions and integrations that allow developers to chain together various components—from data loaders and embedding models to vector stores and LLMs. The primary appeal of these frameworks lies in their promise of accelerating initial development and providing a more organized way to implement retrieval-augmented generation systems.
Despite the apparent convenience of frameworks, a compelling argument exists for direct integration with raw LLM APIs and other underlying libraries. Some developers find that heavily abstracted frameworks can become difficult to use, adding unnecessary complexity and overhead without necessarily improving performance. In many RAG applications, the primary performance bottleneck remains the speed of the LLM API response itself, rather than the efficiency of the framework orchestrating the calls.
Cost Implications
The choice between framework-based and raw API implementations has distinct cost implications:
- Frameworks: While many open-source frameworks are free to use, they still incur costs through their underlying dependencies, such as API calls to LLMs, embedding models, and vector databases. Additionally, the overhead introduced by the framework’s abstractions might necessitate more compute resources to run the application, indirectly increasing infrastructure costs. Managed platforms, like Voiceflow, operate on subscription models with fees tied to credits, knowledge sources, and the number of agents, shifting the cost from infrastructure management to a service fee.
- Raw API: Direct API calls mean paying precisely for the LLM tokens consumed and other cloud services utilized. This approach can lead to lower per-transaction costs if the implementation is highly optimized. The “cost” here primarily shifts from framework complexity and potential resource overhead to the investment in developer time and expertise required for meticulous optimization and custom coding.
For rapid prototyping or applications with less stringent performance demands, frameworks can be a sensible choice. For mission-critical, high-volume, or highly specialized RAG systems, the investment in raw API integration and optimization can yield substantial long-term financial benefits. If you’re evaluating whether to use open-source frameworks or build directly with APIs, understanding the trade-offs in cost, flexibility, and scalability is key.
Conclusions and Recommendations
Assessing the operational costs of RAG pipelines reveals a multi-dimensional landscape where various components interact to shape the overall financial footprint. The following recommendations are put forth for organizations planning or optimizing RAG pipeline implementations:
- Define Clear Requirements Upfront: Before embarking on RAG development, precisely define your application’s latency requirements, desired accuracy, and data privacy constraints.
- Strategize Data Chunking and Embedding: Invest time in optimizing your data chunking strategy and selecting the most appropriate embedding model. A well-thought-out approach here can yield substantial savings.
- Conduct a Thorough TCO Analysis for Hosting: Perform a comprehensive Total Cost of Ownership (TCO) analysis that considers long-term utilization patterns. Cloud solutions are ideal for flexibility and unpredictable, bursty workloads, while on-premise deployments may prove more economical for sustained, high-volume, and highly regulated applications.
- Evaluate Frameworks vs. Custom Integration: Assess the trade-off between the rapid development offered by RAG frameworks and the long-term optimization and control provided by raw API implementations.
- Implement Continuous Monitoring and Optimization: RAG pipeline costs are dynamic and can fluctuate with usage patterns and evolving technologies. Establish robust monitoring systems (e.g., using Prometheus and Grafana) to track key metrics like latency, throughput, and resource utilization, enabling ongoing optimization efforts to control expenses.
By adopting a meticulous and strategic approach to cost assessment and optimization across all components of the RAG pipeline, organizations can harness the full potential of this powerful AI technique while maintaining financial viability and achieving their desired business outcomes.

