
Executive Summary
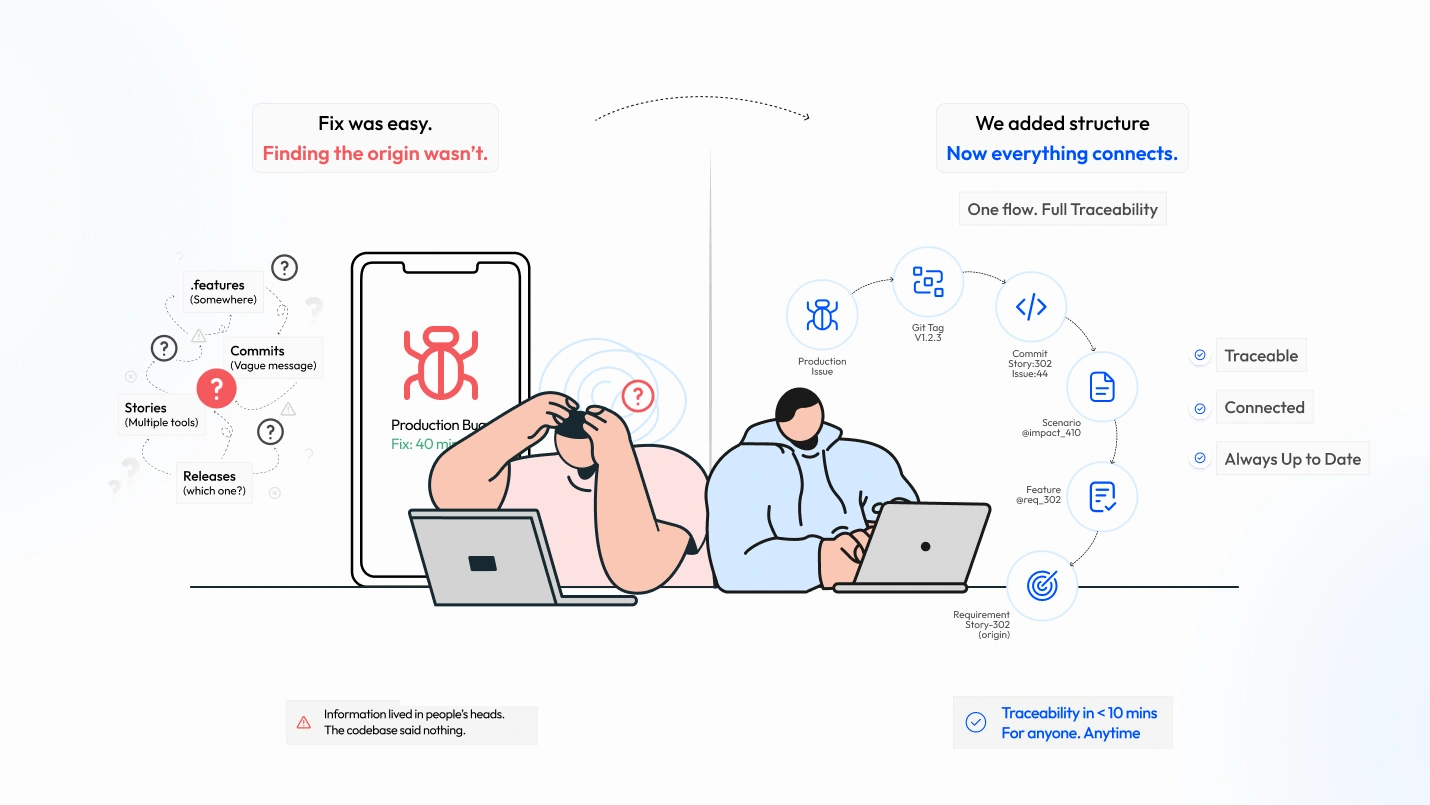
In complex delivery environments where requirements, code, bugs, and test scenarios live across separate systems, a 40-minute fix can take 6 hours to diagnose, not because the code is complex, but because the audit trail doesn’t exist. The failure point? Four systems with no enforced connections. This post documents how we solved that. The tradeoff is discipline over tooling, and that’s intentional.
A production defect recently surfaced in our platform. The fix took only 40 minutes, but nearly 6 hours to diagnose. Tracing it back to its originating requirement, understanding why that code existed, which story introduced it, and which release shipped it consumed time.
This wasn’t a one-off incident. It’s a recurring pattern in environments where delivery spans multiple systems, teams, and tools:
- Requirements live in client-owned Jira/ADO
- Code lives in GitLab
- Bugs are tracked internally
- BDD scenarios sit in a separate test repository
The core issue wasn’t debugging complexity. It was a traceability failure.
We couldn’t answer basic questions quickly:
- Why does this code exist?
- Which requirement introduced it?
- What changed it last?
- Which release shipped it?
If your system can’t answer these in minutes, you don’t have traceability. You have archaeology.
What was the real problem? Four Systems. No Connections.
The .feature files existed for every major capability, were reviewed, and ran in CI. The process appeared healthy on the surface.
However, the underlying convention was missing, which created systemic gaps in traceability. This was not due to lack of effort, but a lack of a strict, codified process that could enforce consistency across a complex, multi-tool environment.
It wasn’t “lack of discipline” or “bad commit messages.” Those are just symptoms. The system failed because it lacked enforced linkage between four entities:
- Requirement (client Jira)
- Scenario (BDD)
- Code (Git)
- Release (tag)
Each entity existed, yet none were reliably connected. These were some failure modes we observed:
- Commits without story/bug references
- Feature files evolving without a history of why
- Bugs tracked internally, but not linked back to requirements
- Release tags with no clear behavioral lineage
Example commit history:
- fix login flow
- update auth scenarios
- PR feedback fixes
These are not just “bad messages.” They are lost intent.
The core failure was not the bug itself, but that the codebase held no record of its own intent. Tracing the full chain required manually searching GitLab commit history, cross-referencing tickets across multiple tools, and eventually asking the developer who last touched the file.
What Traceability Actually Means: Four Questions Your Codebase Should Answer
We defined traceability as the ability to answer these four questions from the codebase alone:
- Requirement → Which business story introduced this behavior?
- Evolution → What changed it last and why?
- Freeze → When was this behavior locked for release?
- Deployment → Which production tag contains it?
Anything less is partial traceability.
Also important: this must work without relying on human memory or external tools.
Why We Rejected External Test Management Tools
We evaluated tools like TestRail and Zephyr.
They failed for our setup due to a synchronization problem, specifically:
- Requirements live in client systems (Jira/ADO, we don’t control)
- Bugs live in our internal tracker
- Tests would live in a third system
This creates three sources of truth.
Since we often work within tools mandated by our clients for managing user stories, engineers are already context-switching between platforms. All incident response and bug tracking are consolidated into a single internal tracker, so a single project runs across at least two platforms before any test tool enters the picture.
In practice, synchronization fails because:
- Engineers don’t update all systems consistently
- APIs don’t capture intent, only state
- Latency between updates creates drift
- Ownership is unclear (who fixes mismatches?)
We could have built integrations. But that introduces:
- Maintenance overhead
- Fragility across client environments
- Dependency on external system availability
We chose a different constraint:
- Traceability must live in the codebase and survive independently of external systems.
The System We Built: Explicit Relationships, Enforced by Convention
We explicitly modeled relationships:
- A Scenario must map to exactly one Requirement
- A Scenario can have multiple Impacts (changes over time)
- A Commit must reference either a Requirement or an Impact
- A Release Tag must be traceable to commits
We enforced this through convention + tooling, not documentation.
The Core Idea: One Internal ID That Everything Maps To
We introduced a Universal Anchor ID (internal tracker ID).
Why internal? Because it is the only system we fully control across clients.
Everything maps to this:
- Client story → mirrored into internal tracker
- Bug → internal tracker
- Commits → reference internal ID
- BDD scenarios → tagged with internal ID
This removes cross-system ambiguity.
How We Embedded Traceability Directly Into BDD Feature Files
We stopped treating feature files as documentation. They became traceability artifacts.
1. Requirement Tag (Origin)
Every scenario must have exactly one requirement:
@REQ_12345 Scenario: Prevent checkout with expired payment method
This is non-negotiable.
2. Impact Tag (Evolution)
Every behavior change adds an impact:
@REQ_12345 @IMPACT_67890 Scenario: Prevent checkout with expired payment method
This creates a visible history of change without relying solely on Git history.
The Real Tradeoffs: What This Approach Costs You
This approach is not free.
Pros:
- Traceability lives close to code
- No external system dependency
- Fast debugging
Cons:
- Manual discipline required
- Tag noise increases over time
- Refactoring scenarios can break historical clarity
- Multiple impacts can clutter scenarios
We accepted these because the reduction in debugging time outweighed the maintenance overhead. The failure mode worth naming explicitly: a missed or misplaced tag creates a silent gap that neither the pre-commit hook nor the pipeline will catch. It surfaces only during investigation – exactly when it is most expensive. Reviewer discipline on the PR checklist is what keeps the chain complete.
Handling Edge Cases
This is where most “clean ideas” break.
1. Multiple Requirements per Scenario
We do NOT allow it.
If a scenario spans multiple requirements, it is poorly scoped. Split it.
2. Scenario Refactoring
When rewriting scenarios:
- Preserve original @REQ
- Add new @IMPACT
- Never delete history silently
3. Deleted Scenarios
We rely on Git history to track deletions.
Trying to preserve deleted scenarios in tags creates more noise than value.
4. Tag Explosion
At scale (1000+ scenarios), tags become hard to read.
Mitigation:
- Periodic cleanup via consolidation
- Tooling to query tags instead of reading manually
Keeping Git History Honest
Tags are useless if commits are not linked.
We enforced:
- Branch: feature/12345 or fix/67890
- Commit: must include [STORY:12345] or [ISSUE:67890]
Example:
fix: handle expired card grace period [ISSUE:67890]
Why Commit-Level Linking Matters
PR-level linking is insufficient because:
- Squash merges destroy commit-level granularity
- Debugging often requires commit-level context
- Blame history becomes meaningless without IDs
The Squash Merge Problem
Squash merges often remove IDs.
We enforced:
- Mandatory manual edit of squash message
- PR checklist validation
Enforcement
We do not rely on memory.
We use:
- Pre-commit hooks (reject invalid messages)
- PR checklist
- Reviewer enforcement
Failure modes still exist:
- Hooks can be bypassed
- Rebases can drop messages
But enforcement reduced violations significantly.
Real Example: Tracing a Bug
Bug: BUG-67890 → Git commit: abc123 [ISSUE:67890] → Feature file: payment.feature → Scenario: expired card → @IMPACT_67890 → @REQ_12345 → Jira: STORY-12345
Actual Scenario
- Production tag: prod-17042026
- Bug: Users in EU could checkout with expired cards (grace period issue)
Trace:
- Search BUG-67890
- Find commit abc123
- Open feature file → see @IMPACT_67890
- Trace back to @REQ_12345
- Identify original requirement: “Strict expiry enforcement”
Root cause:
- A later change introduced region-specific grace logic
- Original constraint was weakened without full regression coverage
Diagnosis time: ~10 minutes
Earlier, this would take hours across systems.
What This Does NOT Solve
This approach breaks or becomes unnecessary when:
- You have a single repo + single Jira
- Teams are small (<5 engineers)
- Strong tool integrations already exist
It also struggles when:
- Requirements are poorly defined
- Teams don’t enforce discipline
- Scenario design is weak
Alternatives We Considered
1. Tool-based traceability (TestRail/Zephyr)
Rejected due to sync complexity
2. Git-only traceability
Insufficient for behavioral intent
3. PR templates + automation
Helpful, but not enough without embedding into test artifacts
Conclusion: Traceability Should Be a Byproduct of Delivery Discipline, Not a Separate Effort
The convention described here did not add a new system. It added structure to things the team was already doing – writing feature files, naming branches, writing commit messages, cutting release tags. The cost was a pre-commit message file and a PR checklist. The return was a tracing time that dropped from most of a day to under ten minutes.
This is the primary argument for convention-based traceability over tool-based alternatives: it lives where the code lives, travels where the code travels, and only degrades if the team stops maintaining it – a risk inherent to any approach, but much harder to ignore when the evidence is in the repository itself.
Key Takeaways
- If traceability depends on memory, it will fail under pressure
- Code without intent linkage is operationally expensive
- Embedding metadata in code is often more reliable than external systems
- Tradeoffs are real: you are shifting the cost from debugging to discipline
- The goal is not perfect traceability. The goal is a fast, reliable diagnosis
FAQs
Not cleanly alongside it. The approach is specifically designed for environments where test management tools create synchronization overhead across systems you don’t fully control. If your Jira, test repo, and bug tracker are all internal and tightly integrated, external tooling may be well-suited to your needs. If any of those systems are client-owned, external tools introduce drift.
Roughly 5+ engineers working across multiple clients or repos. For smaller, single-repo teams with strong Jira integration, the overhead likely exceeds the benefit.
Nothing, entirely. Hooks can be bypassed, and rebases can drop commit messages. The system reduces violations significantly – it doesn’t eliminate them. PR checklists and reviewer enforcement are the secondary layer. Human accountability remains part of the model.
At 1,000+ scenarios, yes – manual readability degrades. The mitigation is periodic tag consolidation and tooling to query tags programmatically. This is a known cost of the approach, not a solved problem.
